梯度
首先要明白什么是导数。导数反映的是函数沿坐标轴方向的变化率。
接着要明白什么是偏导数。所谓偏导数,简单来说是对于一个多元函数,选定一个自变量并让其他自变量保持不变,只考察因变量与选定自变量的变化关系。
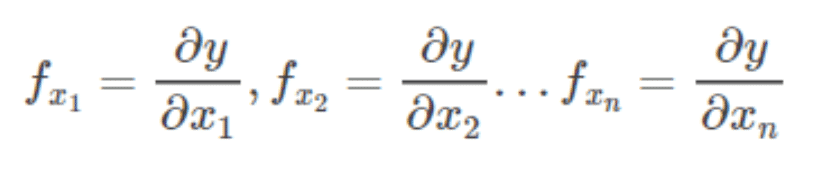
偏导数只能表示多元函数沿某个坐标轴方向的导数。
接着要明白什么是方向导数。除了沿坐标轴方向上的导数,多元函数在非坐标轴方向上也可以求导数,这种导数称为方向导数。很容易发现,多元函数在特定点的方向导数有无穷多个,表示函数值在各个方向上的增长速度。
接着要深刻的认识方向导数是个标量,标量只有大小这一个属性;一个点有多个方向导数,这些方向导数必定存在最大值和最小值。
一堆方向导数里面,只有一个方向上方向导数肯定最大。这个方向就用梯度(grad=ai+bj)这个向量来表示,其中a是函数在x方向上的偏导数,b是函数在y方向上的偏导数,梯度的模就是这个最大方向导数的值。

一个解释很清楚的视频。
https://www.bilibili.com/video/BV1sW411775X?vd_source=de54ea9322a46065441b833723d6c3f1
偏差与方差
模型越复杂,对真实数据就模拟得更加准确,期望值就接近真实值,所以偏差(Bias)就越小;但样本数据就会更加分散,方差(Variance)会增大。相反,模型越简单,就不一定包含真实函数模型,偏差(Bias)就会较大;但样本数据就会更加集中,方差(Variance)会变小。终上所述,模型要选择一个适中,让偏差(Bias)尽可能小的情况下方差(Variance)也小。
如果偏差(Bias)很大,叫欠拟合(underfitting);如果方差(Variance)很大,叫过拟合(overfitting)
预测偏移
预测偏移(Prediction shift)是由梯度偏差造成的。在GDBT的每一步迭代中, 损失函数使用相同的数据集求得当前模型的梯度, 然后训练得到基学习器, 但这会导致梯度估计偏差, 进而导致模型产生过拟合的问题。 我们已经知道TS因目标泄露带来预测偏移。



TS


Order TS
我们发现,常见的TS的编码方式没有平衡好”充分利用数据集“和”目标泄露“。Catboost作者受到在线学习算法 (即随时间变化不断获取训练集) 的启发,提出了Ordered TS。Ordered TS是基于排序原则,对于每个样本的TS编码计算式依赖于可观测的样本。为了使这个想法符合标准线下设定,作者人为构造了”时间“。具体步骤如下:


Catboost流程

另外一种解释。

